如何使用Pandas Value |
您所在的位置:网站首页 › pandas value_counts后分拆为数列 › 如何使用Pandas Value |
如何使用Pandas Value
|
本教程将解释如何使用Pandas的value_counts方法来计算Python数据框中的数值。 它解释了value_counts的作用,语法如何工作,并提供了逐步的例子。 如果你需要特定的东西,你可以点击以下任何一个链接。 目录。 简介 语法 例子 常见问题好的。 让我们来了解一下细节。 对Pandas value_counts方法的快速介绍首先,让我们先解释一下value_counts技术的作用。 本质上,value_counts是对一个Pandas对象的_唯一值进行计数_。 我们经常使用这种技术在Python中进行数据处理和数据探索。 value_counts 方法实际上会对几种不同类型的 Pandas 对象起作用。 潘达系列 潘达斯数据框架 数据框架列(实际上是潘达系列对象)。说到这里,你如何使用value_counts方法,将根据你所操作的对象的类型而略有不同。 此外,还有一些可选的参数,你可以使用它们来改变value_counts的作用。 既然如此,我们来看看语法。 value_counts 的语法好的。 让我们来看看潘达斯value_counts技术的语法。 在这里,我将把它分成不同的部分,所以我们可以看看如何在系列对象上使用value_counts的语法,以及如何在数据帧上使用value count。 简要说明下面的语法解释假设你已经导入了Pandas,并且你已经创建了一个Pandas数据框或Pandas系列。 你可以用这个代码导入Pandas。 import pandas as pd 复制代码关于数据框架的更多信息,你可以阅读我们对Pandas数据框架的介绍。 在潘达斯数据框架上使用value_counts的语法首先,让我们看一下如何在数据框架上使用value_counts的语法。 这真的很简单。 你只需输入数据框架的名称,然后.value_counts() 。
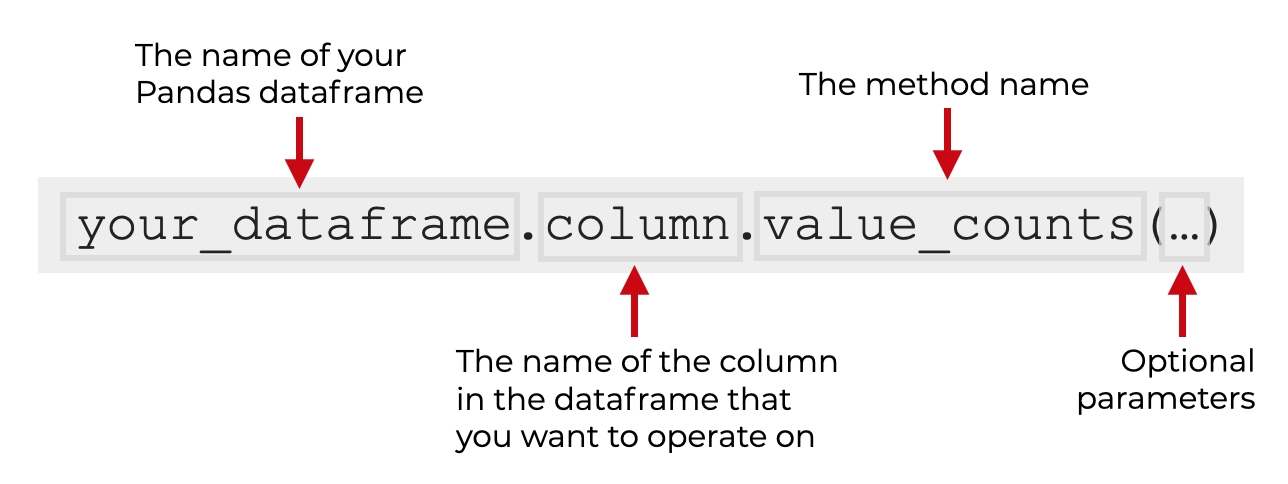
当你在一个数据框架上使用value_counts时,它将计算_每一列_的唯一值组合的记录数。 这可能是比你想要的更多的信息,最好是将数据框架细分到只有几列。 我将在例子部分向你展示一些这方面的例子。 此外,还有一些你可以使用的可选参数,它们将修改方法的行为。 我将在参数部分向你展示这些参数。 在潘达斯系列中使用value_counts的语法接下来,让我们看一下在系列对象上使用value_counts的语法。 系列的语法与数据框架的语法几乎相同。 你只需输入系列对象的名称,然后.value_counts() 。 此外,还有一些你可以使用的可选参数,我们将在参数部分讨论。 在数据框架列上使用value_counts的语法最后,让我们看看如何在数据框架内的_列上_使用value_counts。 记住:单个数据框架_列是_Series对象。 所以要在一个列上调用value_counts,我们首先使用 "点语法 "来检索一个单独的列。 例如,如果你的数据框架被命名为your_dataframe ,而你想检索的列被称为column ,你将开始键入your_dataframe.column 。
之后,你只需输入.value_counts() ,该方法将检索出该列的唯一值的数量。 再一次,有一些额外的参数,你可以用来改变value_counts的工作方式。 让我们看一下这些参数。 数值统计的参数Pandas的value_counts技术有几个参数,你可以使用这些参数来改变该技术的工作方式和具体的工作内容。 ascending sort normalize subset dropna此外,还有bins 这个参数,我很少使用,这里就不讨论了。 值得注意的是,所有这些参数都是_可选的。_ 还需要注意的是,这些参数中的大多数--ascending,sort, 和normalize --都是用于系列语法和数据框架语法的。 另一方面,subset ,只有当你在数据框架上使用value_counts时才可用,而dropna ,只有当你在系列上使用value_counts时才可用。 说了这么多,让我们来单独看看这些参数中的每一个。 ascending默认情况下,value_counts将按数字计数_降序_对数据进行排序。 升序参数使你可以改变这一点。 当你设置ascending = True ,value counts将按照从低到高的计数对数据进行排序(即升序)。 我将在例4中向你展示这个例子。 sort排序参数控制输出的排序方式。 默认情况下,value_counts按_数字计数_对数据进行排序。 你可以通过设置sort = False 来改变这一点,并按类别对数据进行排序。 我将在例5中向你展示这个例子。 normalizenormalize 参数改变了输出的形式。 默认情况下,value_counts显示的是唯一值的数量。 但是如果你设置了normalize = True ,value_counts将显示_总记录的比例_而不是原始计数。 我将在例6中向你展示这个例子。 subset当你在数据框架上使用value_counts时,subset 参数使你能够指定一个应用value_counts的列的子集。 这个参数的参数应该是一个列名的列表(或类似列表的对象)。 因此,例如,如果你想在数据框架中对var_1 和var_2 使用数值统计,你可以使用代码your_dataframe.value_counts(subset = ['val_1','var_2']) 。 注意:同样,这个参数在你对整个数据框架使用value_counts时起作用。 我将在例子7中向你展示这个例子。 dropnadropna 参数使你能够显示'NA'值(即NaN 值)。 你可以通过设置dropna = False 来做到这一点。 注意:这个参数只适用于Pandas系列对象和单个数据框架列。 如果你在整个数据框架上使用value_counts,这个参数将不起作用。 我将在例子2中向你展示这个例子。 例子。获取潘达斯数据框架和系列对象的值计数现在我们已经看过了语法,让我们来看看一些如何使用value_counts技术的例子。 例子。 在数据框架列上使用value_counts 在计数中包括 "NA "值 在整个Pandas数据框架上使用value_counts 以升序对输出进行排序 按类别(而不是计数)排序 计算比例(即对数值计数进行归一化)。 在数据框架列的一个子集上进行操作 先运行此代码在你运行这些例子之前,你需要运行一些初步代码,以便。 导入必要的包 获取一个数据框架 创建一个我们可以操作的数据框架子集让我们一次完成这些。 导入包首先,让我们导入两个我们需要的包。 具体来说,我们需要导入Pandas和Seaborn。 你可以用下面的代码来做。 import pandas as pd import seaborn as sns 复制代码很明显,我们需要Pandas来使用value_counts() 技术。 但我们也需要Seaborn,因为我们将使用titanic dataframe,我们可以从Seaborn的预装数据集中加载。 获取数据框架接下来,让我们来获取我们要使用的数据框架。 在下面的例子中,我们将使用titanic 数据集,或者它的一些子集。 所以在这里,让我们从Seaborn加载数据集。 # GET DATASET titanic = sns.load_dataset('titanic') 复制代码此外,让我们把它打印出来,这样我们就可以看到它的内容。 print(titanic) 复制代码输出。 survived pclass sex age sibsp parch fare embarked class who adult_male deck embark_town alive alone 0 0 3 male 22.0 1 0 7.2500 S Third man True NaN Southampton no False 1 1 1 female 38.0 1 0 71.2833 C First woman False C Cherbourg yes False 2 1 3 female 26.0 0 0 7.9250 S Third woman False NaN Southampton yes True 3 1 1 female 35.0 1 0 53.1000 S First woman False C Southampton yes False 4 0 3 male 35.0 0 0 8.0500 S Third man True NaN Southampton no True .. ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 886 0 2 male 27.0 0 0 13.0000 S Second man True NaN Southampton no True 887 1 1 female 19.0 0 0 30.0000 S First woman False B Southampton yes True 888 0 3 female NaN 1 2 23.4500 S Third woman False NaN Southampton no False 889 1 1 male 26.0 0 0 30.0000 C First man True C Cherbourg yes True 890 0 3 male 32.0 0 0 7.7500 Q Third man True NaN Queenstown no True [891 rows x 15 columns] 复制代码这个数据框架中有15列,如果我们使用value_counts()技术,这将是一个有点困难的工作。 也就是说,让我们快速创建一个子集,我们可以在一些例子中使用。 创建数据框架子集现在,让我们创建一个titanic 数据框架的子集。 这里,我们将创建一个包含两个变量的子集:sex 和embarked 。 为了对这两个变量进行子集,我们将使用Pandas的过滤方法。 #CREATE SUBSET titanic_subset = titanic.filter(['sex','embarked']) 复制代码对于我们的一些例子来说,这个子集会更容易操作,因为它只有两个变量。 例子1:在数据框架列上使用value_counts首先,让我们在一个单列上使用value_counts技术。 在这里,我们将在titanic 数据框架中的embarked 变量上使用value_counts。 让我们运行代码,然后我将解释。 titanic.embarked.value_counts() 复制代码输出。 S 644 C 168 Q 77 Name: embarked, dtype: int64 复制代码 解释执行这个操作的代码是一行代码,但从某种意义上说,它是一个两步的过程。 在这段代码中,我们正在。 用 "点语法 "检索embarked 变量 调用value_counts() 方法因此,我们正在用代码titanic.embarked 检索embarked 变量。 但在这之后,我们用.value_counts() 来调用值计数方法。 在输出中,你可以看到embarked 变量的唯一值 -S,C, 和Q - 以及与每个值相关的计数。 实例2:在计数中包括 "NA "值(仅系列)。接下来,让我们在输出中包括'NA'值(即NaN )。 这将使我们能够看到该变量的 "缺失 "值的数量,如果有的话。 请记住,在这里,我们仍然要对一个单一的数据框架变量进行操作。 titanic.embarked.value_counts(dropna = False) 复制代码输出。 S 644 C 168 Q 77 NaN 2 Name: embarked, dtype: int64 复制代码 解释在这里,我们调用了value_counts() ,就像我们在例子1中做的那样。 唯一的区别是,我们在括号内加入了代码dropna = False 。 正如你在输出中看到的,现在有一个NaN (即 "缺失 "值)的数量。 如果你需要识别缺失的值来清理它们,这可能会很有用,等等。 注意:只有当你在Pandas系列或数据框架列上使用value_counts()时,这才能发挥作用。 如果你试图在整个潘达斯数据框架上使用value_counts(),它将_不会_起作用(如例子3)。 例子3:在整个Pandas数据框架上使用value_counts在上两个例子中,我们在一个数据框架的_单列_上使用value_counts(即一个Pandas系列对象)。 现在,让我们在整个数据框架上使用value_counts。 在这里,我们将在titanic_subset 数据框上使用数值计数。 (记住,我们之前创建了这个子集。 它只有两个变量,以使它更容易操作)。) 好的。 让我们运行代码。 titanic_subset.value_counts() 复制代码输出。 sex embarked male S 441 female S 203 male C 95 female C 73 male Q 41 female Q 36 dtype: int64 复制代码 解释这真的很简单。 要做到这一点,我们只需输入数据框架的名称,然后.value_counts() 。 你可以看到,输出是对数据框架中变量的唯一组合的计数。 请注意,输出是按降序排序的。 这是默认的,但我们也可以改变它,我们将在下一个例子中这样做。 实例4:将输出按升序排序在这个例子中,我们将以升序对输出进行排序。 请记住,默认情况下,value_counts是按_降序_排序的。 但我们可以通过ascending 参数改变这一行为。 让我们看一下。 titanic_subset.value_counts(ascending = True) 复制代码OUT: sex embarked female Q 36 male Q 41 female C 73 male C 95 female S 203 male S 441 dtype: int64 复制代码 解释在这里,我们看到了数据框中唯一的数值组合的计数。 但是现在,因为我们设置了ascending = True ,所以输出是按升序排序的......是从低到高排序的。 例子5:按类别排序(而不是计数现在,让我们完全删除排序。 要做到这一点,我们将用sort = False 来调用这个方法。 titanic_subset.value_counts(sort = False) 复制代码OUT。 sex embarked female C 73 Q 36 S 203 male C 95 Q 41 S 441 dtype: int64 复制代码 解释注意在输出中,数据不是按数值计数(即数字)排序的。 相反,数据是按类别排序的。 两个变量中唯一的分类值是按字母顺序排序的。 我个人认为这更容易阅读,但这确实取决于你在做什么。 可能在某些应用中这样做更好,也可能在某些情况下按数字计数排序会更好(比如默认行为)。 在任何情况下,你都有一个选择。 例子6:计算比例(即,对数值计数进行标准化处理在这个例子中,我们来计算每个独特的数值组合的比例。 在前面的例子中,value_counts 提供了一个数值的计数。 在这里,我们将告诉value_counts 计算总记录的百分比,使用normalize 参数。 titanic_subset.value_counts(normalize = True) 复制代码OUT。 sex embarked male S 0.496063 female S 0.228346 male C 0.106862 female C 0.082115 male Q 0.046119 female Q 0.040495 dtype: float64 复制代码 解释这里的输出与例3的输出有些类似,即按频率降序排序。 但是它不是显示每个独特的类别组合的原始计数,而是显示比例。 注意,如果你把所有的数字加起来,它们加起来就是1。 因此,这些数字再次代表了每个独特组合在总记录中所占的比例。 例子7:对数据框架列的子集进行操作(仅数据框架在前面的例子中,我已经向你展示了如何在pandas Series、小型Pandas数据框架(只有2列)或单个数据框架列上使用value_counts。 这里,我将向你展示如何操作一个有许多列的大型数据框架。 但是我们将使用subset 参数来减少输出的大小和复杂性。 所以在这里,我们将操作完整的titanic 数据框架,它有15列。 我们将使用subset 参数,只对其中的两个变量进行操作:sex 和embarked 。 让我们看一下。 titanic.value_counts(subset = ['sex','embarked']) 复制代码OUT。 sex embarked male S 441 female S 203 male C 95 female C 73 male Q 41 female Q 36 dtype: int64 复制代码 解释在这里,我们正在处理完整的titanic 数据集。 记住:这是有15个变量的完整数据集(而不是较小的titanic_subset 数据框,它只有2个变量)。 因此,在这里,我们正在使用带有15个变量的完整的titanic 数据框架,并且只对2个变量使用value_counts。 要做到这一点,我们要设置subset = ['sex','embarked'] 。 请注意,在语法上,我们想要包含的每个变量都是以字符串的形式出现的(在引号内)。 而变量名的集合被组织成一个Python列表。 关于 value_counts 的常见问题现在你已经了解了 value_counts 并看到了一些例子,让我们回顾一下一些常见问题。 经常问的问题。 当你对数据框架进行操作时,你能使用 dropna 参数吗? 问题1:当你对数据框架进行操作时,可以使用dropna参数吗?很遗憾,不能。 dropna参数对于识别缺失值非常有用,但不幸的是,你只能在对单一数据框架列或Pandas系列进行操作时使用这个参数。 在下面的评论中留下你的其他问题你对Pandas的value_counts技术还有其他问题吗? 是否有一些我在这里没有涉及到的问题让你纠结? 如果是,请在下面的评论区留下你的问题。 想了解更多关于Pandas的信息,请注册我们的邮件列表这个教程应该已经帮助你理解了value_counts技术,以及它是如何工作的。 但如果你想掌握用Pandas进行数据清洗和数据处理的方法,还有很多东西需要学习。 如果你想更广泛地学习Python中的数据科学,甚至还有更多的东西需要学习。 也就是说,如果你已经准备好学习更多关于Pandas和Python中的数据科学,那么请注册我们的电子邮件列表。 当你注册时,你会得到以下方面的免费教程。 NumPy Pandas 基础Python Scikit learn 机器学习 深度学习 ...以及更多。我们每周都会发布免费的数据科学教程。 当你注册我们的电子邮件列表时,我们将把这些免费教程直接送到你的收件箱。 .et_bloom .et_bloom_optin_7 .et_bloom_form_content { 背景色。#999999 !important; } .et_bloom .et_bloom_optin_7 .et_bloom_form_container .et_bloom_form_header { 背景色。#2a2b2d !important; } .et_bloom .et_bloom_optin_7 .carrot_edge .et_bloom_form_content:before { border-top-color:#2a2b2d !important; } .et_bloom .et_bloom_optin_7 .carrot_edge.et_bloom_form_right .et_bloom_form_content:before, .et_bloom .et_bloom_optin_7 .carrot_edge.et_bloom_form_left .et_bloom_form_content:before { border-top-color : transparent !important; border-left-color:#2a2b2d !important; } @media only screen and ( max-width: 767px ) {.et_bloom .et_bloom_optin_7 .carrot_edge.et_bloom_form_right .et_bloom_content:before { border-top-color:#2a2b2d !important; border-left-color: transparent !important; }.et_bloom .et_bloom_optin_7 .carrot_edge.et_bloom_form_left .et_bloom_form_content:after { border-bottom-color :#2a2b2d !important; border-left-color: transparent !important; }.et_bloom .et_bloom_optin_7 .et_bloom_form_content button { 背景色。#4598ab !important; } .et_bloom .et_bloom_optin_7 .et_bloom_form_content .et_bloom_fields i { color:#4598ab !important; } .et_bloom .et_bloom_optin_7 .et_bloom_form_content .et_bloom_custom_field_radio i: before { background:#4598ab !important; } .et_bloom .et_bloom_optin_7 .et_bloom_form_content button { background-color:#4598ab !important; } .et_bloom .et_bloom_optin_7 .et_bloom_form_container h2, .et_bloom .et_bloom_optin_7 .et_bloom_form_container h2 span, .et_bloom .et_bloom_optin_7 .et_bloom_form_container h2 strong { 字体-family:"Open Sans", Helvetica, Arial, Lucida, sans-serif; }.et_bloom .et_bloom_optin_7 .et_bloom_form_container p, .et_bloom .et_bloom_optin_7 .et_bloom_form_container p span, .et_bloom .et_bloom_optin_7 .et_bloom_form_container p strong, .et_bloom .et_bloom_optin_7 .et_bloom_form_container form input, .et_bloom .et_bloom_optin_7 .et_bloom_form_container form button span{字体:"Open Sans", Helvetica, Arial, Lucida, sans-serif; } 注册获取免费的数据科学教程如果你想快速掌握数据科学,请注册我们的电子邮件列表。 当你注册时,你将会收到每周免费的关于如何用R和Python进行数据科学的教程。 给我免费的教程! 检查您的电子邮件收件箱,确认您的订阅 ... |

【本文地址】
今日新闻 |
推荐新闻 |